Key-value accelerator card provider Pliops has unveiled the FusIOnX stack as an end-to-end AI inference offering based on its XDP LightningAI card.
Pliops’ XDP LightningAI PCI card and software augment the high-bandwidth memory (HBM) memory tier for GPU servers and accelerate vLLMs on Nvidia Dynamo by 2.5x. UC Berkeley’s open source virtual large language model (vLLM) library for inferencing and serving uses a key-value (KV) cache as a short-term memory for batching user responses. Nvidia’s Dynamo framework is open source software to optimize inference engines such as TensorRT LLM and vLLM. The XDP LightningAI is a PCIe add-in card and functions as a memory tier for GPU servers. It is powered by ASIC hardware and software, and caches intermediate LLM process step values on NVMe/RDMA-accessed SSDs.

Pliops says GPU servers have limited amounts of HBM. Its technology is intended to deal with the situation where a model’s context window – its set of in-use tokens – grows so large that it overflows the available HBM capacity, and evicted contexts have to be recomputed. The model is memory-limited and its execution time ramps up as the context window size increases.
By storing the already-computed contexts in fast-access SSDs, retrieving them when needed, the model’s overall run time is reduced compared with recomputing the contexts. Users can get more HBM capacity by buying more GPU servers, but the cost of this is high, and bulking out HBM capacity with a sub-HBM storage tier is much less expensive and, we understand, almost as fast. The XDP LightningAI card with FusIOnX software provides, Pliops says, “up to 8x faster end-to-end GPU inference.”
Think of FusIOnX as AI stack glue for AI workloads. Pliops provides several examples:
- FusIOnX vLLM production stack: Pliops vLLM KV-Cache acceleration, smart routing supporting multiple GPU nodes, and upstream vLLM compatibility.
- FusIOnX vLLM + Dynamo + SGLang BASIC: Pliops vLLM, Dynamo, KV-Cache acceleration integration, smart routing supporting multiple GPU nodes, and single or multi-node support.
- FusIOnX KVIO: Key-Value I/O connectivity to GPUs, distributed Key-Value over network for scale – serves any GPU in a server, with support for RAG/Vector-DB applications on CPU servers coming soon.
- FusIOnX KV Store: XDP AccelKV Key-Value store, XDP RAIDplus Self Healing, distributed Key-Value over network for scale – serves any GPU in a server, with support for RAG/Vector-DB applications on CPU servers coming soon.
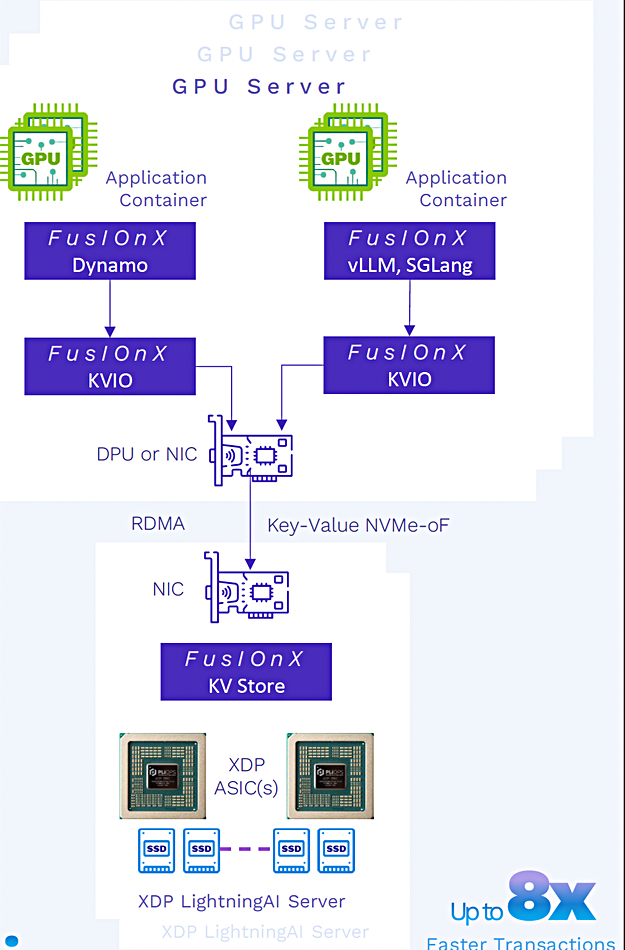
The card can be used to accelerate one or more GPU servers hooked up to a storage array or other stored data resource, or it can be used in a hyperconverged all-in-one mode, installed in a GPU server, providing storage using its 24 SSD slots, and accelerating inference – an LLM in a box, as Pliops describes that configuration.
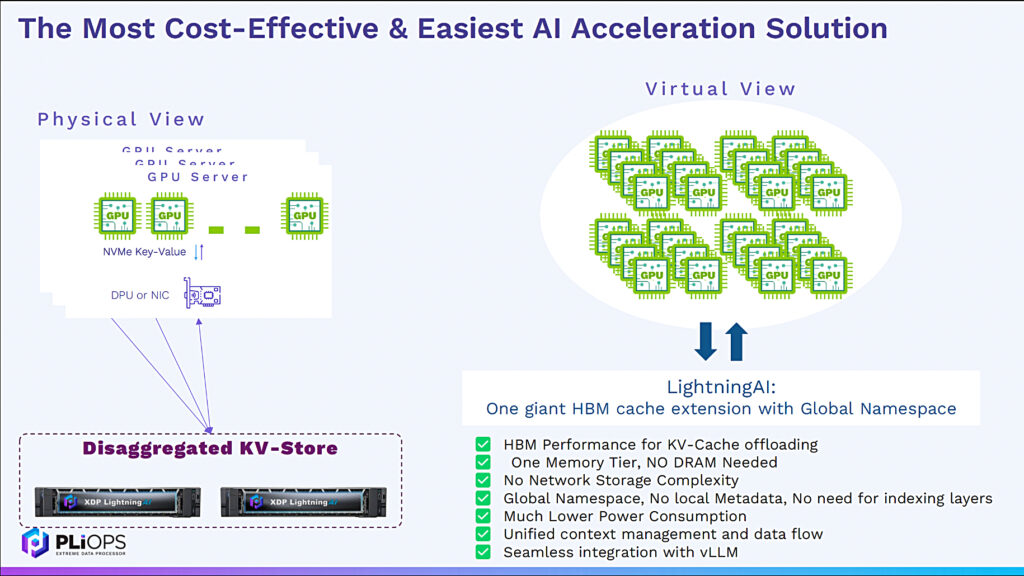
Pliops has its PCIe add-in-card method, independent of the storage system, to feed the GPUs with the model’s bulk data, independent of the GPU supplier as well. The XDP LightningAI card runs in a 2RU Dell server with 24 SSD slots. Pliops says its technology accelerates the standard vLLM production stack 2.5x in terms of requests per second:

XDP LightningAI-based FusIOnX LLM and GenAI is in production now. It provides “inference acceleration via efficient and scalable KVCache storage, and KV-CacheDisaggregation (for Prefill/Decode nodes separation)” and has a “shared, super-fast Key-Value Store, ideal for storing long-term memory for LLM architectures like Google’s Titans.”
There are three more FusIOnX stacks coming. FusIOnX RAG and Vector Databases is in the proof-of-concept stage and should provide index building and retrieval acceleration.
FusIOnX GNN is in development and will store and retrieve node embeddings for large GNN (graph neural network) applications. A FusIOnX DLRM (deep learning recommendation model) is also in development and should provide a “simplified, superfast storage pipeline with access to TBs-to-PBs scale embedding entities.”
Comment
There are various AI workload acceleration products from other suppliers. GridGain’s software enables a cluster of servers to share memory and therefore run apps needing more memory than that supported by a single server. It provides a distributed memory space atop a cluster or grid of x86 servers with a massively parallel architecture. AI is another workload it can support.
GridGain for AI can support RAG applications, enabling the creation of relevant prompts for language models using enterprise data. It provides storage for both structured and unstructured data, with support for vector search, full-text search, and SQL-based structured data retrieval. And it integrates with open source and publicly available libraries (LangChain, Langflow) and language models. A blog post can tell you more.
Three more alternatives are Hammerspace’s Tier Zero scheme, WEKA’s Augmented Memory Grid, and VAST Data’s VUA (VAST Undivided Attention), and they all support Nvidia’s GPUDirect protocols.